Threads are very expensive if you start throwing C++ exceptions within them in parallel. You see the overall time to join the threads increases with each thread you add. There is a mutex in the unwinding code and as the threads grab the mutex they invalidate each other's cache line. I wrote a demo to illustrate the problem https://github.com/clasp-developers/ctak
MacOS doesn't have this problem but Linux and FreeBSD do.
There’s an easy optimization to avoid inspecting every frame when unwinding which c++ could not implement (for policy reasons) though a platform could: add a pointer to the next frame that needs unwinding to the frame setup. This is like move elision.
If my caller has destructors to run or a catch clause this pointer is null and inspection proceeds as normal. If It does not it stores the value from its frame there. Then if I throw an exception I jump to the next frame that needs inspection; if I don’t then any throw further down the call stack won’t even look at me.
The C++ standard can’t call for this because of the “zero cost if you don’t use it” rule. But a Linux ABI could. The MacOS takes advantage of this kind of freedom.
This sounds a lot like the SJLJ runtime model that was used in G++ for years.
> The C++ standard can’t call for this because of the “zero cost if you don’t use it” rule. But a Linux ABI could. The MacOS takes advantage of this kind of freedom.
That's not really true. It has nothing to do with the standard. It has everything to do with the compiler's users complaining about the performance hit relative to DWARF EH. It is part of the social contract between the standards body, the compiler author community, and the user community that unused features don't cost us in runtime performance.
Yes, it's similar I suppose, though much lower overhead. I was a bigger advocate for frame inspection than Michael was in the early years because of my Lisp background. He was (correctly) more concerned with performance.
As for "policy" vs "social contract" I think we basically agree.
To be fair: very few C++ applications are limited by exception performance, it's a feature that's very much out of favor at the moment. So penalizing everyone else (despite the fact that most new code doesn't use them, it's not at all uncommon to find projects with exception generation enabled for the benefit of one library or two) to make parallel exceptions faster actually does seem like a bad trade to me in the broad sense.
Apple does indeed have more freedom, and it may be that specific MacOS components need this in ways that the general community doesn't seem to. But I'd want to see numbers from a bunch of real world environments before declaring this a uniformly good optimization.
> To be fair: very few C++ applications are limited by exception performance, it's a feature that's very much out of favor at the moment.
It is distressing that Sutter's survey showed that half the respondents had to disable exceptions for part of all the code. I've often heard the argument "well google's coding standard prohibits exceptions" which is bizarre, as google's standard says "exceptions are great but we have some legacy code that can't use them, so we're stuck"
The biggest argument seems to be that they are expensive, which is crazy because there's no cost if you don't raise one and if you do you're already in trouble and generally have plenty of time to deal with it (this is different from, say, Lisp signalling which not only permits continuing (!) but is on theory supposed to be common. Probably a mistake in retrospect). But they allow you to make the uncommon stuff uncommon (as opposed to error codes which must be sprayed like shrapnel through your code).
There are two legit arguments against exceptions: one is when you are constrained in space (e.g. embedded systems) and/or time (hard realtime systems that need predictable timing, even if it is slower). The other is a philosophical argument that it embodies a second, parallel flow of control. Since C++'s exception system is an error system only, and since destructors are run automatically, it's hard for me to find this second argument convincing.
> which is crazy because there's no cost if you don't raise one
This is just false in the general case. The presence (potential or actual) of exceptions often just serves as an optimization barrier in current compilers. That's not to even invoke bizarre but not infrequent issues like this [1]. I too have had codebases that miraculously sped up upon disabling exceptions despite not throwing anything. Identifying the exact causes of these situations is hard and typically not done, because it's far easier to just add a compiler switch and pretend there are no exceptions in C++ and get back to work.
Many people in performance sensitive domains just don't find it remotely worthwhile to care about features that have these sorts of difficult to predict and debug costs. When your workflow already consists of writing highly explicit, simple to reason about code that you frequently inspect in disassembled form, exceptions (and RTTI for a host of obvious reasons) are the last thing you'd want to enable. At best it's just extraneous noise in the assembly, at worst you take a sizable perf hit and have no idea why.
A workflow consisting of writing highly explicit, simple to reason about code that you frequently inspect in disassembled form
Is possibly the most descriptive and succinct description of my coding practice. I really like this formulation and I am going to shamelessly steal it in the future, repeatedly.
TL;DR I don’t really use any substantial feature not in C, and basically code C++98, with a few dashes of C++11.
As far as what I’d consider frequent use for me, the only feature I use heavily is namespacing (and that is really only for personal organizational benefits). I do take advantage of standard templated containers and classes when I think they are the right call. Generally, the use of classes and associated method mechanisms are really only used for specific circumstances (which are purely aesthetic for me), and I certainly lean toward custom containers if I can. I do use operator overloading for math, but that’s about it. It is pretty rare for me to use any inheritance, virtual functions, etc, and I don’t think I have ever programmed any exceptions, but maybe some libraries have them, same for RTTI. I do use BLAS, and some other template based libraries.
I don’t use much from after C++98, but I do occasionally dip into C++11 for constexpr. I don’t ever use auto or decltype and I may have looked at range-based fors, but they aren’t used anywhere I can recall.
I think if I could have actual namespaces, instead of space_variable style, C would do it for me. I certainly like that restrict is part of the language, not just a compiler intrinsic. But, and it is a big but, while Clang/llvm, GCC (for the most part) and some proprietary C compilers are good enough for my purposes, MS’s C compiler is barely mediocre as far as I’ve heard (I just went with common talking points when I decided to go down the C++ route, and haven’t actually tested equivalent implementations). Also, while making shim layers is possible, C++ libraries are widespread and common, and just using C++ is less friction and maintenance.
If it isn’t obvious from all of that, my coding style in C++ is basically a rip-off if Mike Acton’s CPPCon talk in 2014. If I want anything more abstract for some reason, I’ll use Python or Haskell or Racket (and recently Ocaml).
Sometimes I miss C++'s flexibility from the managed languages that usually use, then I remember that the community is now driven by the performance at all costs crowd, without exceptions, RTTI, STL and let that thought go.
That is not the C++ I enjoy using, rather the language I got to love via Turbo Vision, OWL, VCL, MFC, Qt, which is not what drives the language nowadays.
I wouldn’t characterize that group as “the community”. True there are a lot of such people, mostly clustered In the game industry where superstition is rife.
Take a look At C++ (or c++ 20!) as if it were a brand new language you’d never seen before and forgetting that it’s name includes “c”. That language is a pretty clean, expressive and straightforward language IMHO. I like programming in it.
It’s not claiming it’s unicorns farting rainbows, but it’s definitely pretty good.
If the community wasn't busy discussing those issues, and constexpr of all things, we would already have reflection, with a concurrency and networking story that isn't put to shame for what Java 5 already had, let alone in modern managed languages.
Yeah, if everyone plays ball, it might come in 5 years from now, assuming C++23 gets done on time, plus the compiler support stabilization.
Right now SG14 seems to drive some of those decisions, at least from outside.
Those are important issues and people who care about them work on them and come to committee meetings. There is less consensus on the concurrency and networking side which I also find frustrating but as I’m not pushing those balls forward I can’t complain. I do think at least that the direction they’re moving in is a fruitful one.
The standard can move quickly: consider formatted output which lingered unchanged with a broken model but was rapidly reformed when someone with a good model and implementation was encouraged to come forward. Admittedly a smaller topic than concurrency or networking!
Right now, the way I see it, I rather help the managed languages I work on reach the point where binding to C++ is kind of last option when nothing else helps.
The other language communities manage to drive language progress over the Internet, which apparently ISO has yet to get in touch how it goes.
C++ does this as well, for example with boost, where several things that entered the standard got their start. And the format example I gave. It’s the ISO blessing that is complex, but also acts as a forcing function tromtrhnto make new features as orthogonal as possible. Sure, it’s not to everybody’s taste, but you don’t need to follow ISO if you don’t wish to.
Well I can afford a complete ABI break (complete) given the kind of code I work on. Most people cannot. Binary incompatibilities are very hard for most people to manage.
So I would benefit from any number of abi-breaking proposals but can understand the committees reticence.
To be honest it is hard to not break ABI. First you almost surely need to use PImpl and second hope a compiler upgrade keeps the standard library ABI compatible(eg ABI version flags in gcc). For a good look at how hard this is look at breakages in gentoo. This is basically the reason the greater open source community has their libraries in C: stable ABI, and consequently language bindings.
Unless i am missing something big the concept of ABI stability in C++ is an art and requires a lot of discipline. At the top of my head only KDE was somehow successful but have a look at their guidelines[1]: again it requires a lot t of discipline.
Also I believe that ABI compatibility with binaries compiled with different compilers also is complicated by things like name mangling conventions which are not common between compilers.
There are so many things that can go wrong that the people i know that rely on ABI compatibility in C++ make a diff of their objdump output a ci test. Sometimes they get more paranoid and send me an assembly diff when they are suspicious(a compiler upgeade generated different jump prolog:) ). Ridiculous compared to the price of just running the compile again. The fact we control the whole machine's os image even makes it harder to understand... Oh man the pain I have...
My apologies if my text is weird but proof reading in a phone is hard.
Per HN's own guidelines your post did not deserve downvoting.
Unfortunately some people do use downvoting to mean "I disagree", presumably based on the convention of some other forum. There's not much to be done about that except upvoting posts you see have been unfairly downvoted.
Yeah, when the moderates move out, the hard core that remains swings towards what makes C++ unique, and that's not general purpose application programming and language features that support it.
Which looking from its use in mainstream OS SDKs means drivers, composition engine, shaders and real time audio engines, the SQL of systems programming, kind of.
You shouldn't use exceptions in cryptography as well.
There are constant-time concerns and dumping sensitive data in the heap concerns at the very least.
Writing exceptions-safe code is not free in itself. Surely one can do it, but it requires more mental energy to write and even more efforts to review the code.
> it's a feature that's very much out of favor at the moment.
I'm glad if it is so. Exceptions should actually be "exceptional" and not the part of the normal execution flow. Whoever has other ideas has the wrong model of what, at the lower levels, exceptions actually do.
This sounds interesting - thank you! We need to interoperate with C++ - so we couldn't use this, could we? We could add this pointer to our own frames but C++ frames won't have this info - so I'm not sure how they would interoperate. We need to be able to throw an exception and invoke both Clasp frame cleanups and C++ frame cleanups up the stack. We have a crazy mix of C++ and CL frames on the stack at any time.
Sure you could. You presumably already have a mechanism for doing frame unwinding either via compatibility with the C++ runtime's throw() implementation or by supplying your own. So for your own stack frames you can do what you like. Exceptions raised by c++ code called from lisp would also work the same way as they do now.
And when you are unwinding a lisp->C++ boundary (that is, lisp code called by a C++ function) you are free to do what you like until you get to the first Lisp frame; if it doesn't have an unwind-protect then its "ignore me" pointer just points up to its caller, which is examined by the C++ runtime anyway.
The nice part of that second paragraph is that if that first lisp callee was called by a non-c++ function (say a fortran function) you might even have an opportunity to set the "parent frame for inspection pointer" to skip over all the fortran frames and point directly to the lowest C++ function below you...which you could manage via a small change to gold or llvm-ld.
In libgcc it's in Unwind_Find_FDE - we think it's a lock around walking the loaded dynamic libraries. I haven't personally dug much deeper into it but my folks here and the llvm engineers seem to be pretty certain that's the problem (this: https://github.com/gcc-mirror/gcc/blob/master/libgcc/unwind-...). Right now we are rearranging our compiler so we throw fewer exceptions because you don't have to optimize things that you don't do :-).
Looks to me like it only tries to protect the building of the shared / sorted "seen_objects". You don't want two threads rebuilding it at the same time. Although there must be a way to work around this. Maybe something like optimistically walk through the seen list, then grab the lock to update and walk again without a lock? You should be able to safely walk a linked list forwards even with another thread inserting into it, right?
I think that this is a lock around dlopen(). dlopen changes the list of mapped objects (and therefore, the mapping from instruction pointer to unwind information).
Thank you. We have developed a Common Lisp implementation that uses LLVM and interoperates with C++ and uses C++ exception handling to unwind the stack. Common Lisp code relies on stack unwinding a fair bit. Imagine my surprise when my fancy multi-threaded compiler can't get out of first gear (tops out at ~150% cpu) on Linux. Sheesh.
It's going well. I'll post something soon. We've just been working on it quietly. We have multithreading, unicode, cffi etc, good debugging support, cross-language profiling and more.
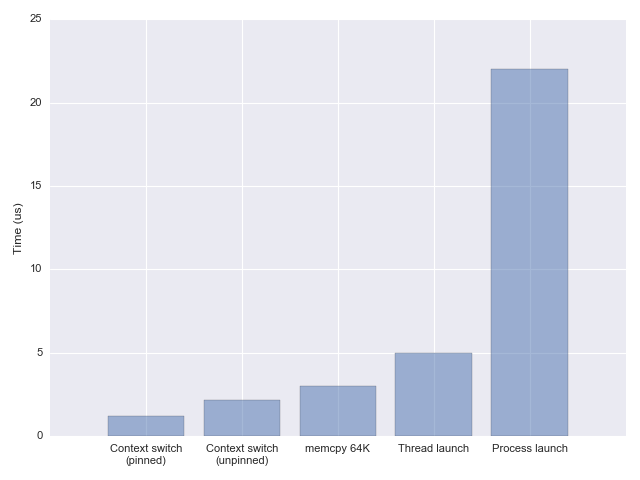
I find Eli Bendersky’s writeup [1] more useful as it actually goes closer to the details. For readers less familiar, it also makes it more clear what the time spent will depend on (how much state there is to copy). Eli’s post is actually a sub-post of his “cost of context switching” post [2] which is more often applicable (and helps answer all the questions below about threadpools).
For CPU-bound tasks, it is best to pre-create a number of threads whose count roughly corresponds to the number logical execution cores. Every thread is then a worker with a main loop and not just spawn on-demand. Pin their affinity to a specific core and you are as close as possible to the “perfect” arrangement with minimized context switches and core-local cache data being there most of the time.
One thing to worry about is that you’re effectively taking over the job of the OS scheduler. This can be a good thing since you know more about your workload than the generic heuristics the scheduler uses, but it also means that you might need to reimplement some things.
Like only scheduling work on logical cores that share a physical core after all physical cores have a busy logical core (I.e. fill up the even cores first).
Taking over the job of the OS scheduler is explicitly the reason for doing it, there are some classes of macro-optimization that have this as a prerequisite. It is done for the same reasons that high-performance database kernels replace the I/O scheduler too.
To your point, it is a double-edged sword. Writing your own schedulers requires a much higher degree of sophistication than using the one in the OS. It is a skill that takes a long time to develop and requires a lot of first principles thinking, there is loads of subtlety, you can't just copy something you found on a blog. It also isn't just about being able to predict the behavior of your workload better than the OS, you can also adapt your workload to the schedule state since it is exposed to your application, the latter being a greatly overlooked capability.
Once you know how to design software this way, it not only generates large increases in throughput but also enables many elegant solutions to difficult software design problems that simply aren't possible any other way. While the learning curve is steep, once you are accustomed to writing software this way it becomes pretty mechanical.
> One thing to worry about is that you’re effectively taking over the job of the OS scheduler.
Exactly. And some apps automatically do that by default, as if they are so arrogant as to think they must be the only program running on that machine. Maybe good for a server app, terrible advice for a general desktop app.
Yep. We do this on real hardware and never preempt. There is nothing more performant than that. Using IPIs (inter-processor interrupts) you can trigger events like "more work has been added" on each CPUs queue.
Additionally, when you put all interrupts of a device solely on one specific CPU you won't have to lock anything.
Some other things:
pthreads generally have high cost, and that means C++ threads do too. pthreads have quite a few features that you regularly don't use, which you can skip completely using fibers and coroutines.
How many percent performance do you think you gain by never pre-empting?
If we're talking 50%, the complexity sounds worth it, but if it's 1% I think I'd prefer to stick with standard scheduling and know my program will 'just work' on any CPU or OS, and with any libraries I choose to use.
Probably a lot on bare metal, but we are a special case here. It really brings down the latency to respond to network events. A single context switch is in the range of 100K-1M CPU cycles.
The reason why is because we avoid all the indirect cost of context switching, which is all the various caches that has to be flushed. And also the context switching itself, of course.
However, you can still do a lot on Linux to equalize things if you really want to get down to it. For anything but special cases Linux really does a good job with scheduling. After all, you are likely not running much else other than your intended service.
That said, for me this thread was a slight wakeup-call that made me look more into fibers and co-routines. I have been wanting to use these for a long time for some things.
> A single context switch is in the range of 100K-1M CPU cycles.
1M cycles is roughly 300 microseconds (assume 3 GHz processor, so 3 cycles is 1 nanosecond). Eli’s graph from the post I referenced above, has a context switch in the 1-3 microsecond range [1] depending on taskset/core pinning. The high end (3 microseconds) is about 10000 cycles then.
Maybe you mean fork() or pthread_create for your 1M cycles?
The difference can be quite large, details are workload and software dependent. It isn't just the context-switching overhead (which is prohibitively high these days), it also significantly improves average cache locality, which is the bottleneck for many high-performance codes.
Some types of software optimizations require the ability to correctly infer local CPU cache contents, which is difficult when arbitrary processes are semi-randomly stepping all over that cache.
I don’t think this is a realistic expectation on Linux and, especially, Windows which runs hundreds of threads of its own you don’t want to know about. (Besides, we must remember that multithreading was invented and found quite useful in the era of ”single-core” processors.)
On a server running heterogeneous CPU-bound tasks of various users it is hardly a realistic expectation, but on a single-user device with a single application in the foreground I would say it is realistic, since most of these running processes are blocked on something most of the time. Hundreds of mostly-idle resident processes are insignificant to a one that puts the CPU through its paces.
I learned recently that even with isolcpu, and nohz, and interrupts directed elsewhere, the kernel will still pause the thread on the isolcpu if it has mmapped a file (e.g., to report stats) and the kernel decides it's time to copy the bits to disk. If you don't want stalls, only map writable files on a tmpfs volume. To snapshot the file, copy it to another file on the same volume, and then snapshot the copy.
Yes, it is called TLB shootdown and it is required to preserve the integrity of the TLB across CPUs on an umap or a dirty bit change. If latency is impprtant, don't use disk backed writeable mappings.
Edit: to clarify: any writeable mapping or any unmap will cause TLB shutdown interrupts to be broadcasted to all currently running threads of a process.
Of course one never unmaps the file, or any mapped memory, so this has nothing to do with TLB problems (which are also a thing -- another reason processes are better than threads).
These pauses happen even without unmapping. Despite that no synchronization is available, so you are right in the middle of whatever, the kernel decides a static snapshot of the pages' state must be written, so write-protects the pages first, and blocks your process until the write is done. It's just rude.
Unmapping is one case. As I said earlier, the other case is clearing the dirty bit for a page in the in the page directory. As the dirty bit is cached in the tlb (so it doesn't need to be written back every time the page is written by a cpu), the tlb need to be flushed. I do not think the kernel write protects the page is writing out, unless the architecture has no hardware dirty bit and one must be maintained by the os. Technically tlb shootdown is not a form of blocking, but it does cause periodic latency spikes.
Multi-millisecond latency spikes in a process spinning on an atomic update cannot be blamed on TLB flush, which introduces stalls measured in, at worst, microseconds.
This thread is about the performance of threads, which we have established can be a high cost for some. In our case we don't run on Linux or Windows, but you can still do the same on Linux afaik, although you will have to write a kernel object for some things.
Exactly this. You want one thread pool of size ~= core count, then you want to have a completely different "max number of IO jobs" type deal that doesn't use threads at all.
C# async/await is pretty good for this (IO operations do not count towards CPU task count).
Paraphrasing the famous Greenspun’s Tenth Rule, any home-made threading library for C++ always ends up being “an ad hoc, informally-specified, bug-ridden, slow implementation of half of” Intel TBB. (Been there, done that.)
This is not about coming up with a thread library. The described scenario can be realized entirely with standard Pthread primitives and calls like pthread_setaffinity.
Even if you pre-create a thread (thread pool), when the task is small enough (less than 1,000 cycles), it is less expensive to do it in place (for example, with fibers), because of the cost of context switching.
Agree. A few years ago I noticed a C program we used in production spawned a new thread for each incoming connection. Since the vast majority of these just served two small requests (think two HTTP gets) I tried adding a very simple thread pool that would keep up to four idle threads around. To make a thread wait for work I used an eventfd (Linux). I tried a linked list and an array for the idle threads. I tried protecting the get/return code with a mutex and spin lock, and then made it lock free with C11s atomics. Two days later I still couldn't get this to be faster than just spawning a new thread every time, so I gave up this experiment.
It seems at least the Linux folks optimized the crap out of clone() over the last years.
> It seems at least the Linux folks optimized the crap out of clone() over the last years.
The most essential Linux benchmark is compiling the Linux kernel (since it's something the Linux kernel developers do all the time, so they really feel the impact). The clone() system call is used both to create new threads and to create new processes, and the Linux kernel compilation uses a large amount of short-lived processes (each C file is a new C compiler process). It's only natural that clone() is heavily optimized, together with the filesystem caches (each new C compiler process reads the source code files from scratch).
Thread spawning should only become a problem for very high concurrent client counts (ie, large N). How many concurrent clients did this program have?
When I ran benchmarks to compare a thread-per-client model to a single-threaded, event-based one, the single-threaded throughput was around 2 to 3 times higher for as few as 1000 clients.
Not many, slightly above 800 on average iirc. It wasn't even a bottleneck or anything, I was just curious how much impact it would make. That's also why I didn't bother trying to change it to event based with single thread or one thread per CPU core, as that would've been way more work than two afternoons so just not justified.
Because threads are traditionally created and scheduled by the OS, so it inevitably involves a costly context switch both first into the kernel and then back again into the next thread, if one is ready.
Userspace threads are more light-weight, but probably still worse than just using fibers and co-routines. Depends on your needs, I suppose.
Switching threads require entering the kernel which costs from a few hundreds to thousands of clock cycles (and it got worse from all the spectre/meltdown mitigations).
A fiber switch can be done in less than 10 clock cycles.
C++20 has apparently a fix for it with std::jthread, though.
With all possible the learnings from Java, .NET, Erlang, TBB, Concurrency Runtime, and yet ISO C++ did not manage to get a proper concurrency story, and it full of traps like the one you mention.
Another one is std::async, which might actually be synchronous, depending on a set of factors.
A related question if anyone knows good answers here.
What programming languages' de-facto thread implementations are not wrappers around pthreads? I think Go has its own thread implementation? Or am I mistaken?
Java does not specify the actual threading model, so you can get green threads (user space) or red threads (kernel threads).
The upcoming Project Loom, intends to make it so that green threads become the default (aka virtual threads on Loom), but you can still ask for kernel threads, given that is what most JVM implementations have converged into.
GHC Haskell's runtime has a "default" light-weight thread system (forkIO) that schedules logical threads on the available operating system threads and parallelises them across available CPUs:
> A newly spawned Erlang process uses 309 words of memory in the non-SMP emulator without HiPE support. (SMP support and HiPE support both add to this size.)
And a word is the native register size, so 4 or 8 bytes these days, so fairly small, but not 64 bytes small.
Is this even possible on a 64 bit architexture? The default stack size is, I think, 2mb, and i have previously allocated terabytes of VM space without issues.
Not making a jab at what you are saying, but to me “running out of virtual memory” has always sounded like a crazy thing, like running out of address space. Sure, given enough disk space, your program might get (quite) a bit slower, but it should still chug along just fine. Yet, running out of virtual memory is indeed still a thing, especially in Windows (a workaround being using memory-mapped files).
Why is there such a big difference in timing between Skylake and Rome? Something compiler specific? The number of steps required to create a thread should be identical.
I’ll also be interested to see the same benchmark but using pthread_create directly.
All your worries, if throughput is all you worry about, and not latency. Or, if you have interaction between threads. Or, if you might need to run on other archs.
An equivalent to TBB or GCD will be in C++23 std libraries, but you can often do better with coroutines, in 20.
TBB and GCD still need to sychronize sometimes, and they randomize workload assignment, which is bad for cache locality (i.e. bad). If you can arrange static assignment and avoid need to synchronize, you can do better, sometimes much better.
The problem with C++23, is that it will be mostly usable around 2025, and C++20 co-routines still don't have a co-routine aware standard library, right?
Executors, which abstract threads, coroutines, fibers, vector units, GPUs, and very possibly even spin-polling isolated cores, will be integrated in 23. In the meantime you have the core language features, if you don't need or want abstraction, and Boost asio, which will get everything ahead of time. But std algorithms integrated to use the abstract executors optimally may not surface until 23, IIUC. I don't know why you would need to wait for 2025.
You may reasonably expect C++23 library features to show up in (or by) 2023, just as C++20 features will be out in this calendar year. You might have private reasons to delay adopting C++23 until 2025, but there is nothing the rest of us can do about that.
Java TPL is very, very limited when compared to C++23 executors.
"Concurrency", by the way, has come to refer to the synchronizing interactions that cause slower-than-xN parallelism.
Java executors exist and are useful to me today in all platforms where a Java compiler is available, C++ executors are yet to be delivered, it remains to be seen what C++23 will actually look like and what will be dropped at very last minute like contracts were.
Also other programming languages also don't stand still.
Are you suggesting that C++ is developing too slowly? Others complain that it is changing too quickly. Maintaining the right balance is hard, but choosing a balance point everyone can agree on is impossible.
The mode chosen by the C++ committee is to favor development of library features outside the Standard, and then adopt the successes. That entails waiting to see what is a success, and relying on non-Standard library implementations in the meantime. The '23 executors design has been a long time coming, but is overwhelmingly better -- meaning, applicable to a much broader space of execution models -- than early designs, without compromise on performance. Other languages routinely compromise on performance, which is often the right choice for them.
My personal best practice is to always create a thread pool on program startup and distribute your tasks among the thread pool. I use the same best practice in all other languages too. Is this best practice sound or can it lead to problems in some corner cases?
There are lots of details that might cause problems:
* Do your tasks block? How many threads do you need to make sure you can use all your CPUs.
* Do your tasks access different sets of memory? Would keeping similar tasks on the same CPUs reduce cache misses.
* Do your tasks have different priorities? You might need a pool for each priority.
For a UI program that isn’t doing anything really intensive or real-time, having a common thread pool makes a lot of sense, and can reduce resource use (stacks add up once you get to many 10s or 100s of threads...), and improve latency (a work queue with many threads will get more CPU than another with the same amount of work but fewer threads)
I used nodejs for a project, and assumed that "it's all javascript on one thread" would leave threading issues behind.
My application curiously stopped responding whenever I had 5 or more users. Connected users could continue to do anything, but new users couldn't connect, and existing users sessions would hang when executing any code that wrote to a logfile, making debugging even harder. Using the nodejs debugger, the internals of write(...., cb) were just never calling the done callback.
After hours of head scratching I found that most IO from nodejs is not asynchronous and callback based as the docs suggest, but is in fact blocking IO done from worker threads. My process was using pipes to communicate with other processes, and those pipes were doing blocking writes, and when blocked, the worker thread was blocked.
There are 4 worker threads by default, so whenever 5 users were using the system, all worker threads were tied up and it would fail. It would have been nice for nodejs to at least have printed to the console "All worker threads busy for >1000ms. See nodejs.com/troubleshooting/blockingfileio.htm" or something.
As far as I'm aware, node.js is a wrapper over libuv which is a truly asynchronous socket IO library. It fakes file IO async ops with thread pools because on Linux file IO isn't async at all.
* Do you have sufficiently large batches that you can efficiently assign to one thread?
If not, then you're just wasting a lot of time waking up to receive inputs, assigning them to threads (-> put them on a work queue or similar, with all the locking / atomics), and waking up a thread to pull an item (locking / atomics), process it, go to sleep...
It's easy to end up spending more time juggling tasks and switching tasks than performing any useful work.
The thing I would worry about here is that perhaps not all of your tasks have the same performance demands. There may be tasks related to RPC that should run as quickly as possible and tasks related to computation that could take a long time. If all of the threads in the threadpool are busy with an expensive computation there could not be left any to quickly handle RPC requests.
I personally prefer to do as much as possible just in one thread, where you can run things asynchronously with a single threaded message loop and then have a thread pool next to that for expensive computations. This also tends to reduce the number of things that need to be protected with a mutex.
{kind=link}
MacOS doesn't have this problem but Linux and FreeBSD do.